Mapping¶
A Mapping algorithm allows you to state what values will replace the original data. It maps original data values to masked values that are pre-populated to a lookup table through the Masking Engine user interface. There will be no collisions in the masked data because it always matches the same input to the same output. For example “David” will always become “Ragu,” and “Melissa” will always become “Jasmine.” The algorithm checks whether an input has already been mapped; if so, the algorithm changes the data to its designated output.
You can use a Mapping algorithm on any set of values, of any length, but you must know how many values you plan to mask. You must supply AT MINIMUM the same number of values as the number of unique values you are masking; more is acceptable. For example, if there are 10,000 unique values in the column you are masking you must give the Mapping algorithm AT LEAST 10,000 values.
The Mapping Algorithm can be configured for mappings managed locally on the Masking Engine or remotely on a customer managed PostgreSQL database. The remote configuration should be used if the customer wishes to more easily manage the storage allocated for mappings, or if there is a desire to share the same Mapping Algorithm mappings across multiple Masking Engines. More information about remote mapping configuration can be found here.
Info
Masking Engine 6.0.9.0 and earlier: When you use a Mapping algorithm, you cannot mask more than one table at a time. You must mask tables serially.
Masking Engine 6.0.10.0 and later: A single Mapping Algorithm can have multiple jobs running concurrently.
Tokenization/Reidentification¶
Given the nature of Mapping Algorithms, they can be used with Tokenization
and Reidentification jobs. However, if ignoreCharacters are configured for the
algorithm, Tokenization/Reidentification cannot be used.
Note
The character mapping algorithm can be used for tokenization and reidentification jobs.
Sync¶
Mapping Algorithm can be synced in 1 of 2 ways:
-
Syncing a locally managed Mapping Algorithm: This can be done to effectively make a copy of an algorithm from one Masking Engine to another. In addition to syncing the algorithm, the mappings must be manually exported from the source engine and imported into the target engine. Once this is complete, the 2 algorithms (on the source and target) will have the same names and initial set of mappings (at the time of sync) but will function as 2 separate algorithms. That is to say, adding new mappings on the source will not have any impact on the algorithm on the target.
-
Syncing a remotely managed Mapping Algorithm: This can be done to share the same Mapping Algorithm across Masking Engines. In this case, once synced, the algorithm on the source and target(s) would point to the SAME remote mapping database. This would mean that adding/removing/manipulating the mappings would affect the algorithm on all engines that use it.
For more information on sync, see here.
Creating a Mapping Algorithm via UI¶
-
In the upper right-hand corner of the Algorithm tab, click Add Algorithm.
-
Select Mapping.
-
The Create Mapping Algorithm pane appears.
-
Enter an Algorithm Name.
Info
This MUST be unique.
-
Enter a Description.
-
Select whether or not the mappings will live locally or remotely, by toggling the Local Mapping Store checkbox appopriately. If using a local mapping store, proceed to step 9.
Info
For more information about remote mapping stores, click here.
-
Specify Host/IP, Port, Mapping Database, and Schema of the remote database.
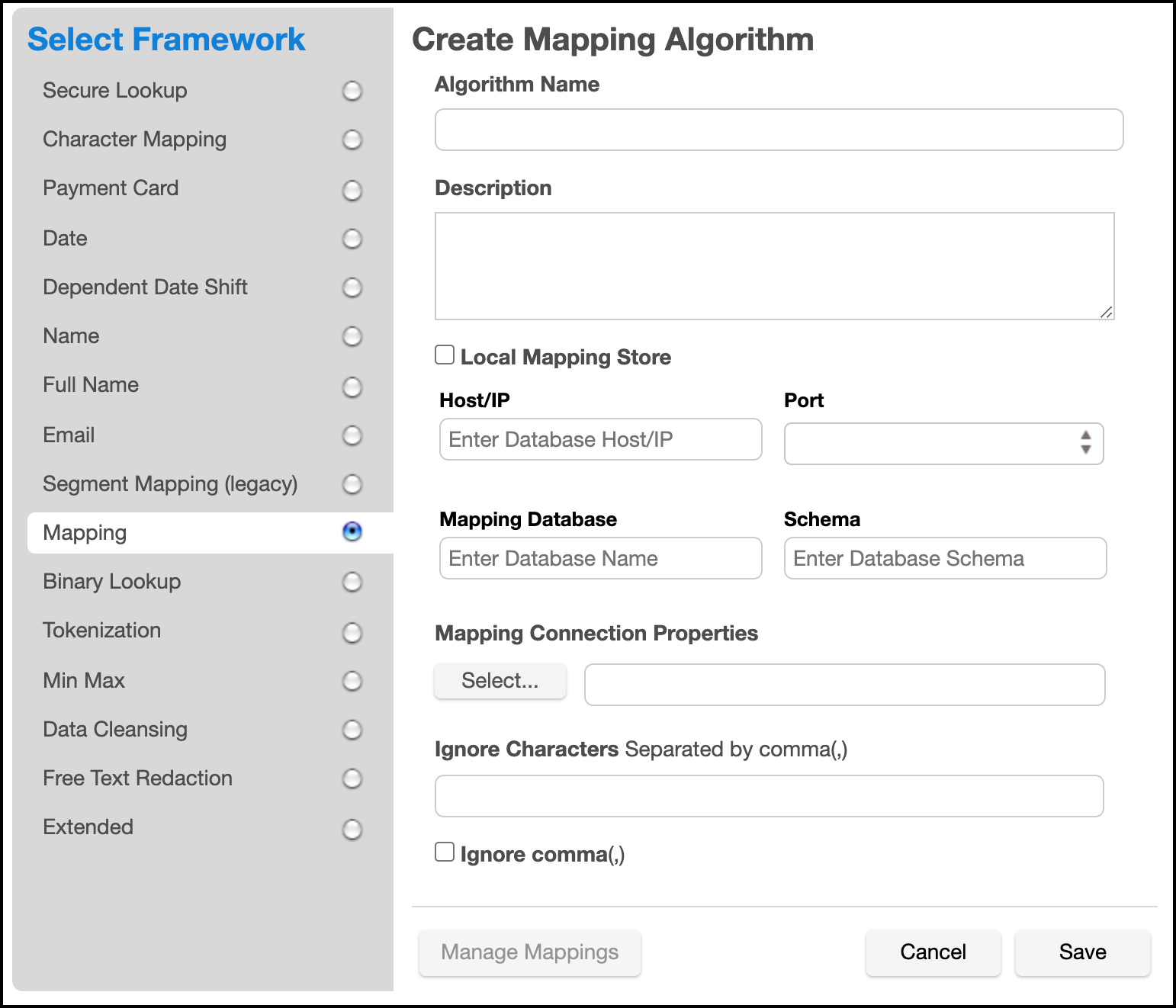
-
Enter any remaining connection parameters in a properties file specifed by the Mapping Connection Properties field.
-
To ignore specific characters, enter one or more characters in the Ignore Character List box. Separate values with a comma.
-
To ignore the comma character (,), select the Ignore comma (,) checkbox.
-
When you are finished, click Save.
Before you can use the algorithm by specifying it in a profiling job, you must add it to a domain. If you are not using the Masking Engine Profiler to create your inventory, you do not need to associate the algorithm with a domain.
For information on creating Mapping algorithms through the API, see API Calls for Managing Algorithms - Mapping.
Managing Mappings via UI¶
Regardless of where the mappings reside (local or remote), the management process is the same.
To start go to the Edit Mapping Algorithm screen and select Manage Mappings
At the top there are 2 statistics provided for the mappings:
-
Total Mappings is the number of mapping outputs that exist for this algorithm.
-
Available Mappings is the number of mappings that have not yet been assigned to an input value.
Info
When a job using the Mapping Algorithm runs, the mappings are loaded into memory. This means that enough memory must be provided to the job to load the mappings. A Mapping Algorithm with 2GB worth of mappings will require a job with a larger configured XMX than what is needed for a Mapping Algorithm with 2MB worth of mappings.
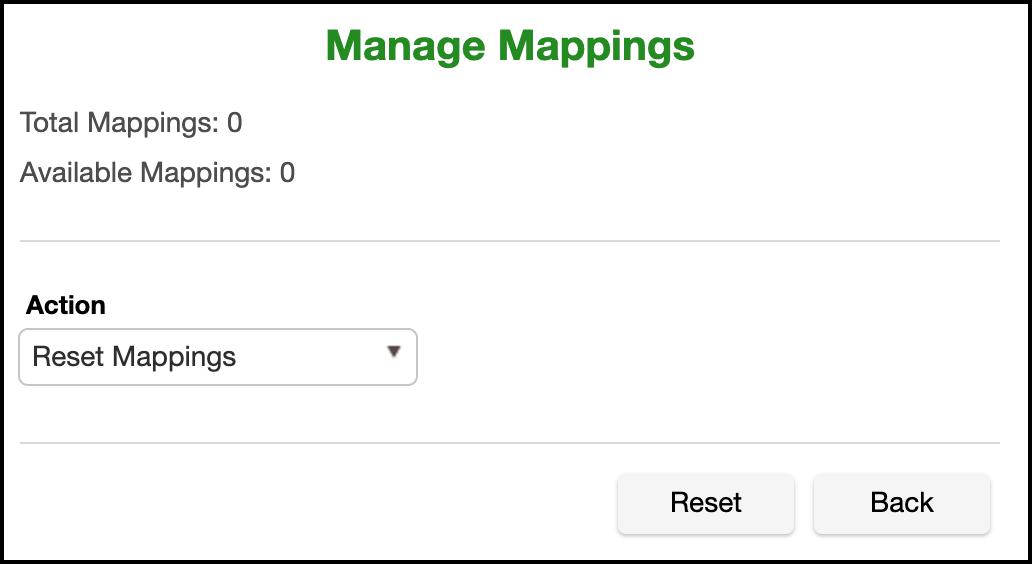
In addition to the mapping statistics there are 4 actions to choose for managing mappings:
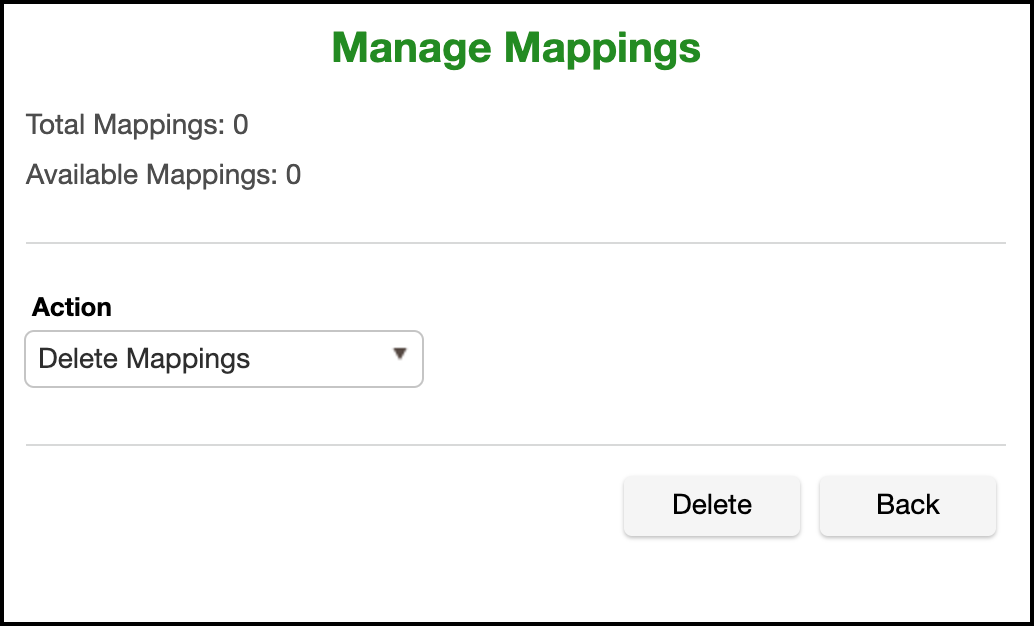
Delete Mappings¶
This action will delete all input/output combinations and effectively start this algorithm fresh. For this option to take effect you must select the Delete Mappings action and then click Delete.
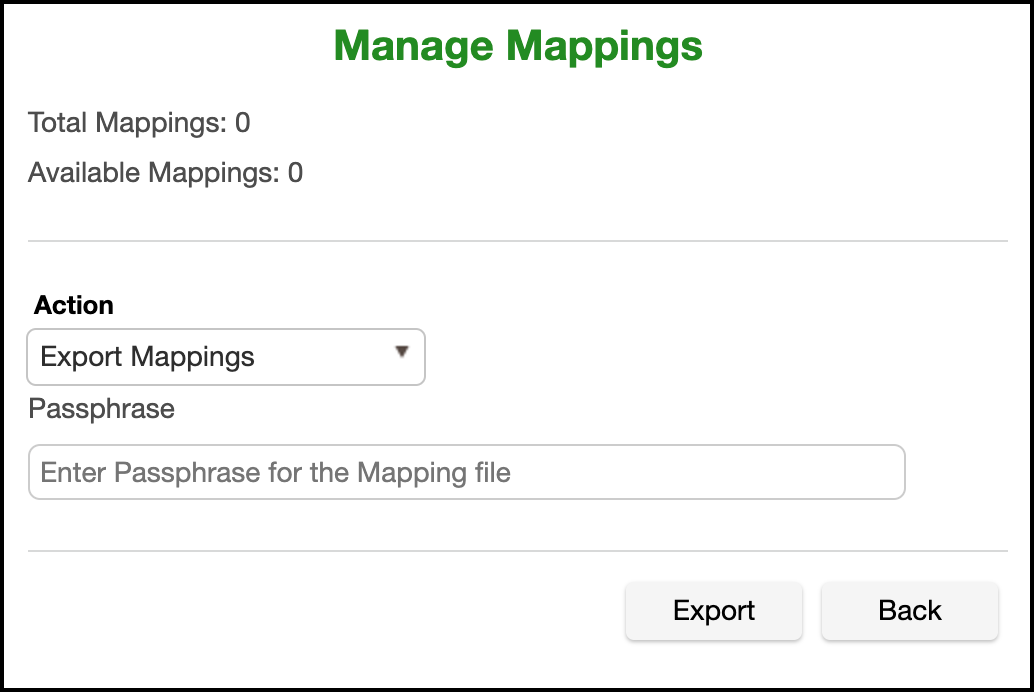
Export Mappings¶
This action will export all mappings into a file that can then be used to seed another mapping algorithm or to simply have a list of established mappings. For security purposes a passphrase is required to encrypt the file on export.
To export mappings select the Export Mappings action and provide a passphrase and then click Export.
Once the export file has been generated a link that says Click here to Download File will appear. Click this to download the export file.
Info
If you wish to decrypt the exported file from the command line, run the following command:
openssl enc -aes-128-cbc -a -d -pass stdin -pbkdf2 -iter 100000 -md SHA256 -in PATH_TO_EXPORT_FILE
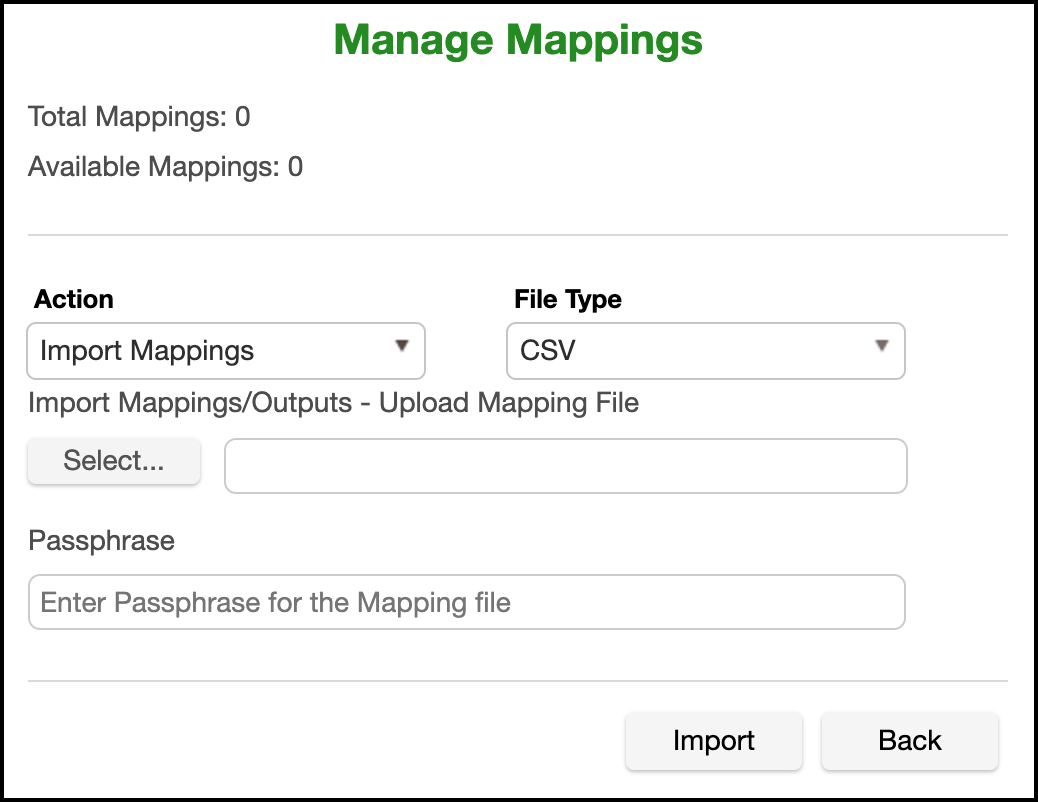
Import Mappings¶
This action will add mappings to the mapping algorithm. Mappings can be provided in 2 different formats - PLAINTEXT and CSV.
PLAINTEXT¶
A PLAINTEXT mapping file can ONLY provide mapping outputs (i.e.: values you want to mask to). The file must have NO header. Make sure there are no spaces or returns at the end of the last line in the file. The following is sample file content. Notice that there is no header and only a list of values.
Smallville
Clarkville
Farmville
Townville
Cityname
Citytown
Towneaster
CSV¶
A CSV mapping file can provide both mapping inputs and outputs. That is, you can determine beforehand what you want your mappings to be. The CSV file MUST have ONLY 2 columns - input and output. The first line of the file MUST be the header "input,output". The following is a sample CSV mapping file.
input,output
New York,Smallville
Boston, Clarkville
San Francisco, Towville
"",Cityname
"",Citytown
"",Towneaster
Info
You may opt not to specify an input, but you must specify an output for a line to be considered valid. Invalid lines are silently ignored.
Once a File Type is selected, choose the mapping file in the Import Mappings/Outputs field.
Info
If providing a previously exported mapping file which has been encrypted with a passphrase, select the CSV file type, provide the unaltered encrypted file and provide a passphrase.
When the appropriate selections have been made, click Import.
Info
Any duplicate values provided will be silently ignored.
Reset Mappings¶
Ths is action will delete all inputs for provided mappings, giving you a mapping algorithm with as many outputs as you had before, but with all of them available for assignment the next time the mapping algorithm is used.