Tokenization¶
The Tokenization framework allows you to mask data and reverse its masking. For example, you can use a Tokenization algorithm to mask data before you send it to an external vendor for analysis. The vendor can then identify accounts that need attention without having any access to the original, sensitive data. Once you have the vendor’s feedback, you can reverse the masking and take action on the appropriate accounts.
The Tokenization algorithm is designed to be used in Tokenization/Re-Identification jobs, though it can also be used in Masking.
The algorithm tokenizes values using AES-128 encryption in CBC-CTS mode, with an optional initialization vector (IV), and Base64 encoding. The results are alpha-numeric strings that are longer than the original values. If the result is too long to fit in the field, the algorithm can be configured to either (a) fallback to a reversible masking algorithm, which produces a result that is the same length as the original value, or (b) fail the job.
The algorithm has the following properties:
- The masked value for each input is consistent when using the same algorithm and the initialization vector length is 0. Changing the key for the algorithm or using an initialization vector length greater than 0 will result in different masked values.
- As long as at least one maskable character is present in the input, the masked value will never match the input.
- The algorithm used to mask a value can change depending on the length of the input.
- The algorithm only works on string data types. Numbers can be masked if the column data type is a String type, such as VARCHAR or TEXT.
This new algorithm framework was introduced in version 6.0.13.0 to replace the existing Tokenization algorithm and adds the ability to select a fallback algorithm.
Creating a Tokenization Algorithm via UI¶
-
In the upper right-hand region of the Algorithms tab under Settings, click Add Algorithm.
-
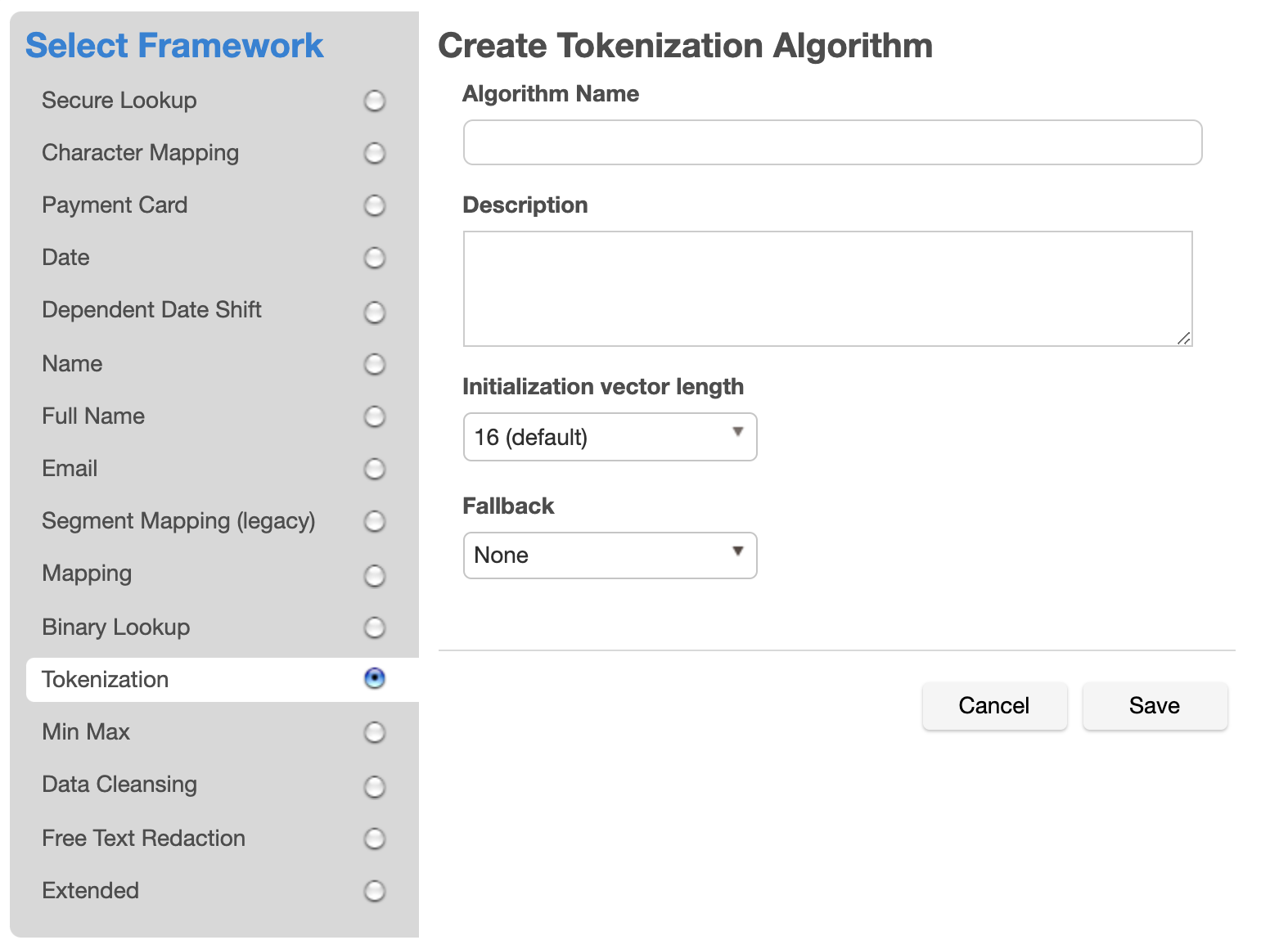
Select the Tokenization Framework. The "Create Tokenization Algorithm" pane appears.
-
Enter an Algorithm Name.
Info
This MUST be unique.
-
Enter a Description.
-
Select an Initialization vector length. The default length is 16, which offers the most security. The tradeoff is that this increases the length of the masked result. Selecting a lower IV length decreases the length of the masked result. It is recommended that you only select an IV length of 0 if you require the masked value for each input to be consistent between jobs and for the same input to only mask to one output.
-
Select a Fallback algorithm. An AES encrypted result is always longer than the original value. If an AES encrypted result is too long to fit into the field, the job will fail if Fallback is "None". When Fallback is "Character Mapping", the Character Mapping algorithm is used to tokenize the value, which produces a result that is the same length as the input.
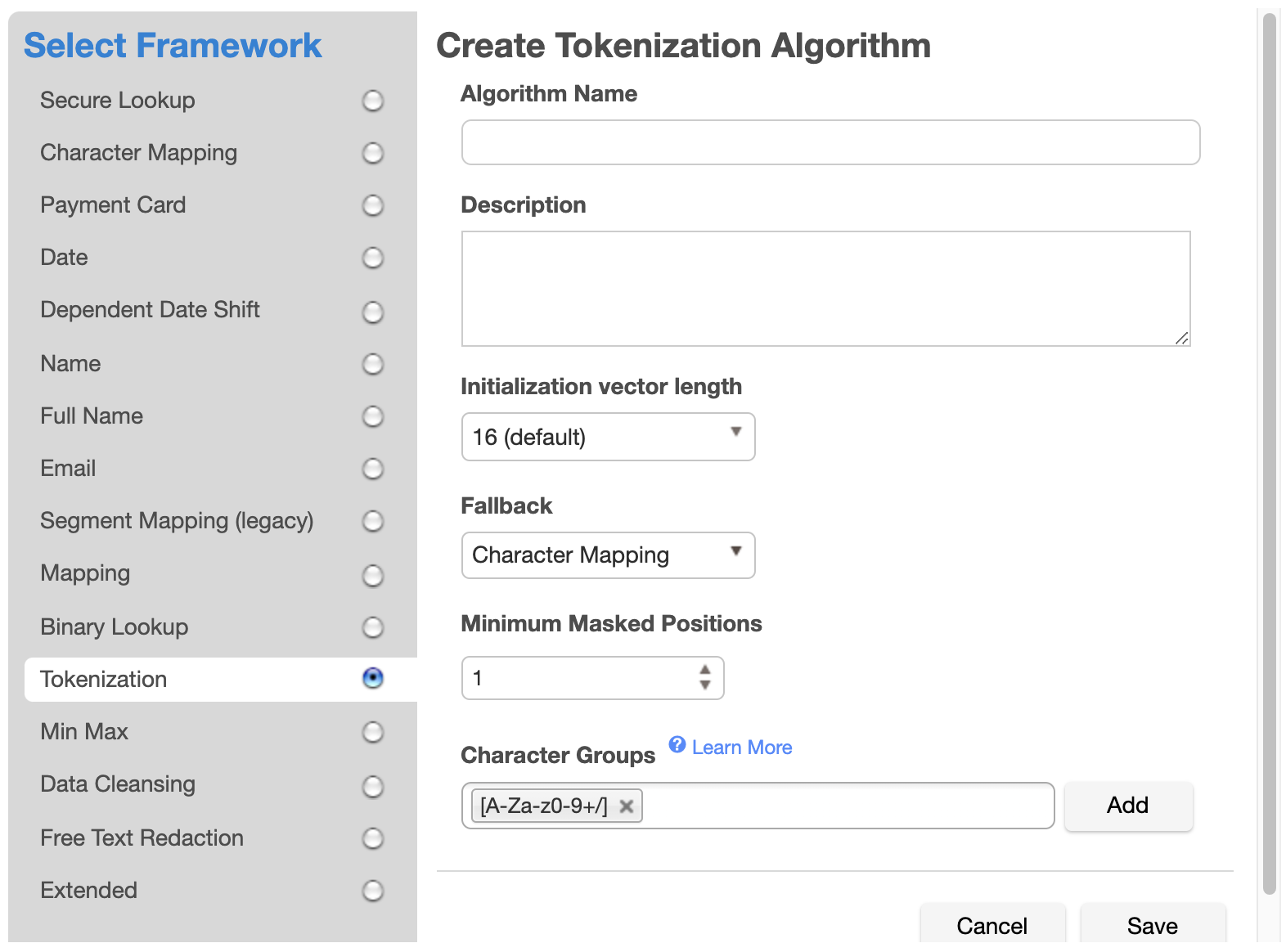
If Character Mapping is selected as the Fallback, a Character Mapping algorithm is created, which will be used to tokenize values that cannot be tokenized with AES encryption because the encrypted result is too long for the field. When selected, two additional configuration options will appear: Minimum Masked Positions and Character Groups. Unlike standalone Character Mapping algorithms, the Character Mapping algorithm used for Tokenization fallback does not support Preserve Ranges and Preserve Leading Zeroes, and Case Sensitive is permanently set to true.
-
Enter a value for Minimum Masked Positions, which sets the minimum number of characters that the algorithm must mask; fewer positions triggers non-conformant data handling. Null, empty, and all-whitespace values never trigger non-conformant data handling.
-
Define Character Groups for each group of characters among which you would like to map. Each group may be defined either by specifying each literal character in the group, such as "0123456789", or using Java Regular Expression style character ranges, such as "[0-9]". The algorithm will freely map characters to other characters within the same group, so by defining groups "[0-9]" and "[A-Z]", numbers would be replaced by other numbers, and letters by other letters, but a number would never be replaced by a letter. Groups should not contain duplicate characters, and each character may belong to only one group. Any character that is not assigned to a group will be preserved (not masked) by the algorithm. It is recommended that all characters are in one group so there is more randomization and the values are more obfuscated. The default is the Base64 character set ["[A-Za-z0-9+/]"], which contains the same characters that appear in an AES encrypted result.
Once you have created an algorithm, you may associate it with a domain.
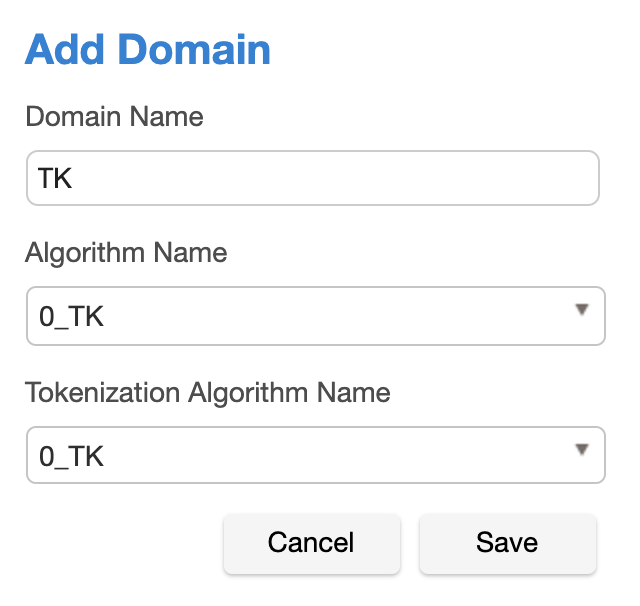
- In the upper right-hand region of the Domains tab under Settings, click Add Domain.
-
Enter a Domain Name.
-
Select algorithms from both the Algorithm Name and Tokenization Algorithm Name drop-down menus.
Next, create a Tokenization Environment:
-
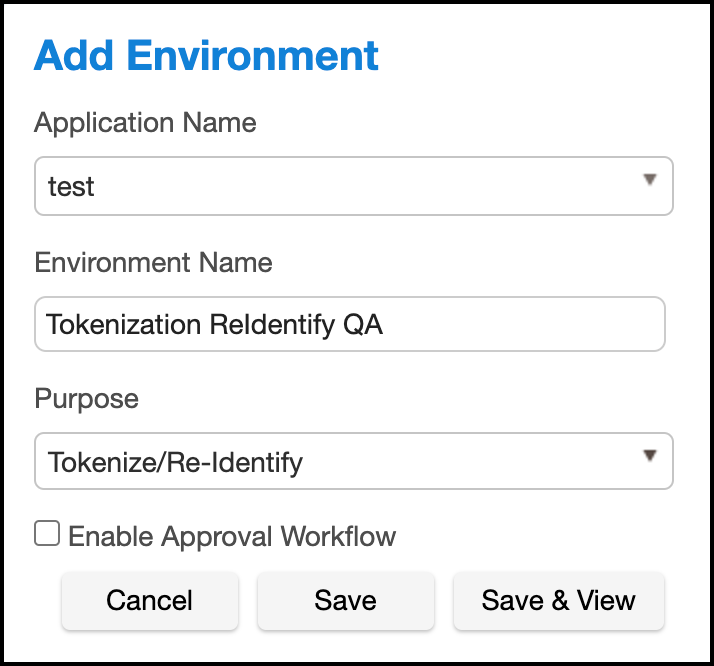
In Environments, use the Select Action dropdown menu to select Add Environment.
-
For Purpose, select Tokenize/Re-Identify.
Info
This environment will also be used to re-identify your data.
-
Set up a Tokenization job using the Tokenization Method. Execute the job.
Examples¶
Here is example data before and after Tokenization:
Before Tokenization
1,Erasmus,245 Park Ave,123-45-6789
2,Salathiel,245 park ave,123-45-6789
3,Salathiel,1003 Stant Drive,111-11-1111
After Tokenization
ID,fname,address,ssn
1,FQL71CmqK/pkd8B2vVP903O4+/krT91dscS0rKQRACQ=,XFLst0IcSbOa2UlEOmlACPkcaOEVczZsEdxl225kF1M=,x6tJ4eyL4it4ji84h8PzoCW4QBZphEqDOy3hEj4h1jE=
2,4bGZoCLpbV2zAMsTkcc5lMTBKksvOP+tfAWucq+BnKM=,OA9dJ5HN5oRx18ZYo1f5Y8DofvhFoRo98cuQHZ7YeEo=,Evj+LnETt7ABbXlTDPyNvvJe8WJnrhEWeS0lqtqrr4U=
3,Ll4T49FrCBYRibOAKOY4vbnswbOn1RpqBU97EGg4RvA=,f6AR0T+HBoTW7+l0e8ok9rImj872PUnYYNYMDYSy4dw=,wYMvEhktV371kqH607afJHZloT+4DYNJxehWIcPZJzI=