Name¶
Starting in version 6.0.8.0, Delphix has introduced a builtin Extensible Name Algorithm Framework, co-existing with the legacy FIRST NAME SL and LAST NAME SL ones. Name Framework provides masking functionality for String type input. It's based on Secure Lookup mechanism, and includes additional configuration flags making it more flexible and robust.
Similar to Secure Lookup it creates masking results which are determenistic (i.e. the same algorithm with the same configuration and security key will provide the same result for the same input) and not unique. So it you are looking for the framework whose algorithm(s) will provide a unique masking results you should consider using other frameworks (for example Character Mapping).
The new framework uses SHA256 hashing method and allows case configurations for input and output (i.e. masked) values. It also allows filtering accents, configuring the maximum length of the masked value. If input name is a multi-word string it might contain particles, related to the name. By particles we consider any prefixes, suffixes, titles, etc. The new framework allows configuring which particles to be removed, and which to be preserved.
Creating a Name Algorithm via UI¶
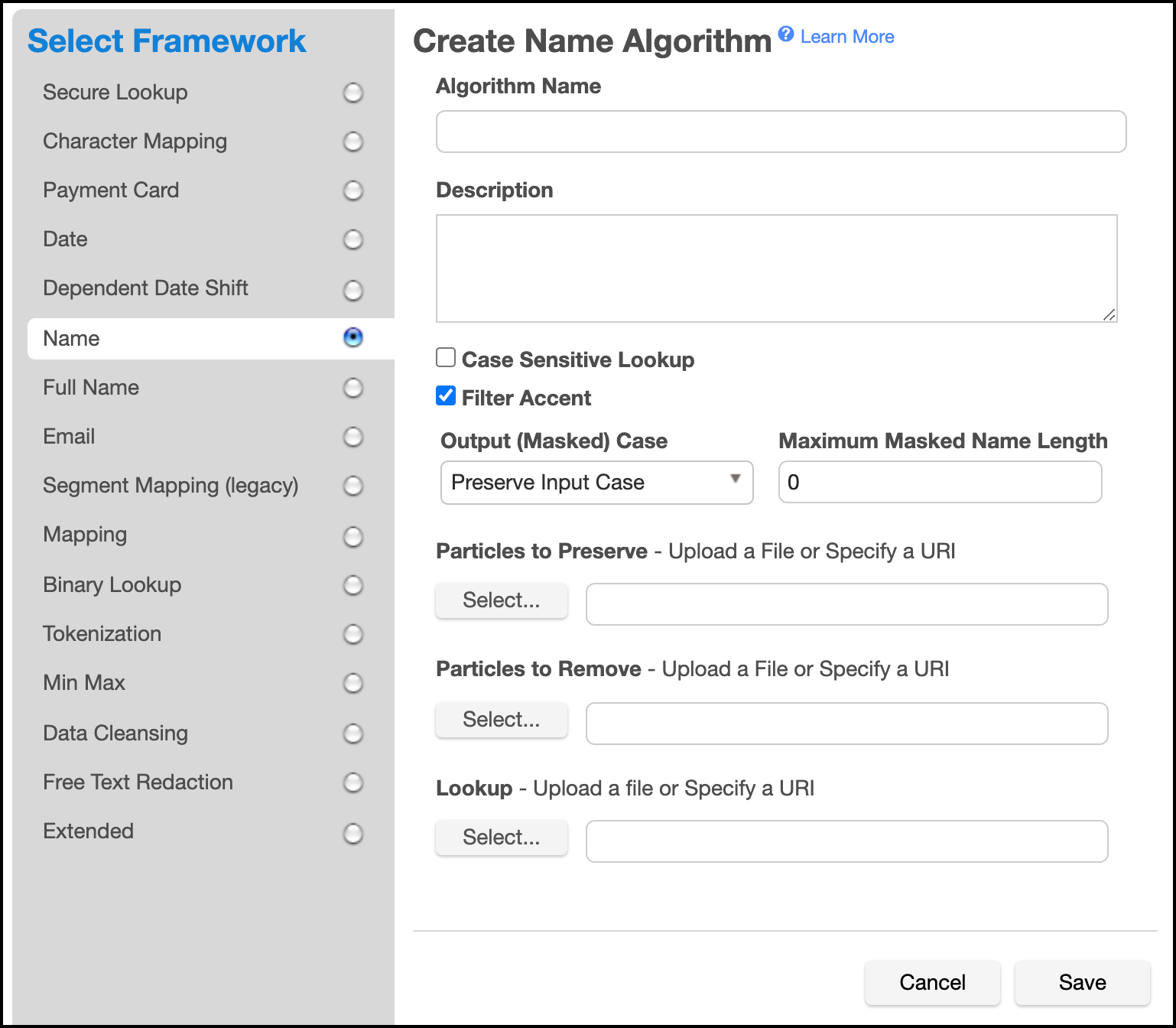
-
In the upper right-hand corner of the Algorithm tab, click Add Algorithm.
-
Choose Name Framework. The Create Name Algorithm pane appears.
-
Enter an Algorithm Name. (Required)
Info
This MUST be unique on the Masking Engine.
-
Enter a Description. (Optional)
-
Choose the Case Sensitive Lookup configuration. (Optional. Boolean. Default is false)
If Case Sensitive Lookup box is marked than the same input of different cases will be masked to the different values. For example:
Peter -> John peter -> AndrewOtherwise it will be masked to the same values, for example:
Peter -> John peter -> John -
Choose the Filter Accent configuration. (Optional. Boolean. Default is true)
If Filter Accent box is marked than the similar input with and without accented symbols will be masked to the same values. For example:
Adrián -> John Adrian -> JohnOtherwise it will be masked to the different values, for example:
Adrián -> John Adrian -> Peter -
Choose the Output (Masked) Case configuration. (Optional. Enum. Default is Preserve Input Case)
It is explained with the examples in the information popup window, which may be opened by clicking on the blue "? Learn More" sign on the above Create SL Algorithm window. The Name Framework pop-up window displays the following text.
Info
This is the framework to cover the sections where it is required to mask string with deterministic and not unique masking results
Framework Options:
Output (Masked) case:
- Preserve Lookup File Case - keep masked value as found in the Lookup File.
-
Preserve Input Case (Default) - check the input case, which can be one of the following three:
- All uppercase - in that case force whole masked value to uppercase
- All lowercase - in that case force whole masked value to lowercase
- Mixed (if at least 1 character case is different from others) - in that case keep masked value as found in the Lookup File
-
Force all Uppercase - forces whole masked value to uppercase
- Force all lowercase - forces whole masked value to lowercase
Maximum Masked Name Length: Max number of characters or length of masked output string. default is 0., which means unlimited.
Case Sensitive Lookup: A flag to configure if input value case should be considered for Lookup match or not. default is off/false.
Filter Accent: A flag to configure if accent character in input should be considered for Lookup match or not. default is on/true.
Particles to Preserve (Optional): A file with list of words those should be preserved while masking. ex, "Mr.","Mrs.","Sir" etc.
Particles to Remove (Optional): A file with list of words those should be removed while masking. ex, "Mr.","Mrs.","Sir" etc.
Lookup File (Required): A file with list of values for masking.
-
Choose the Maximum Masked Name Length configuration. (Optional. Integer. Default is 0)
This number should be >= 0 (i.e. not negative). That's the maximum number of characters masked result should fit. I.e. masked result is trimmed to that length. Value 0 means length is unlimited.
Info
We're also trying to detect the length of the destination field. Some Data Sources provide that value, while others don't. For example: if Data Source provides value 10 for the destination column length and current configuration field is set to 0 or any value longer than 10 - the shortest value wins, i.e. in this example masked result would be trimmed to 10 characters.
Warning
Some UTF-8 characters might take 2 bytes. If lookup file contains those characters - the trimmed result might be not as expected, since we trim by the number of characters and not number of bytes. There is a bug open for that mismatch.
-
Specify a Particles to Preserve File. (Optional. Locally chosen file, or a FileReference) Contains particles to be preserved. I.e. those particles are not masked. For example if file contains particle "von" and "Froum" is masked to "Smith" than
von Froum -> von Smith -
Specify a Particles to Remove File. (Optional. Locally chosen file, or a FileReference) Contains particles to be removed. Those particles are removed prior to masking, i.e. they do not affect masking result. For example if file contains particle "von" and "Froum" is masked to "Smith" than
von Froum -> Smith Froum -> SmithInfo
If particle is found in both "Preserve" and "Remove" files - it will be removed.
-
Specify a Lookup File. (Required. Locally chosen file, or a FileReference)
This file is a single list of values. It does not require a header. Every line of the Lookup File might be used as a masked value. The Lookup File must be ASCII or UTF-8 encoding compatible. The following is sample file content:
Ann Marie Tomas Ann-Marie Basil Mark -
When you are finished, click Save.
For information on creating Name algorithms through the API, see API Calls for Creating Algorithms - Name.