Introduction to Masking Algorithms¶
Overview¶
This article provides a brief outline of the different algorithm options that are available, along with other general algorithm information. More specific algorithm details can be explored in the Out Of The Box Algorithm Instances or Algorithm Frameworks sections.
An algorithm plugin can be configured through the graphical user interface by entering the plugin's required configuration in JSON format. For more information, visit the General UI for Extended Algorithms article.
Algorithm Options¶
Out Of The Box Algorithm Instances¶
Out of the box algorithm instances are pre-configured ready to use algorithms. The out of the box algorithms with related frameworks can be customized using the corresponding extensible frameworks. For more information on algorithm instance extensibility, see Extensible Algorithms.
Algorithm Frameworks¶
Algorithm frameworks allow for creation of algorithm instances with a custom configuration. For more information on algorithm framework extensibility, see Extensible Algorithms. More information on multi-column algorithms can be found at Using Multi-Column Algorithms.
| Algorithm Framework | Extensible? | Multi-Column? | Out of the Box Instances |
|---|---|---|---|
| Binary Lookup | X | ||
| Character Mapping | X | dlpx-core:CM Alpha-Numeric dlpx-core:CM Digits |
|
| Data Cleansing | |||
| Date Replacement | X | ||
| Date Shift | X | Date Shift Fixed | |
| Dependent Date Shift | X | X | |
| X | dlpx-core:Email Unique dlpx-core:Email SL |
||
| Free Text Redaction | X | ||
| Full Name | X | dlpx-core:FullName | |
| Mapping | X | ||
| Min Max | |||
| Name | X | dlpx-core:FirstName dlpx-core:LastName |
|
| Payment Card | X | Credit Card | |
| Regex Decompose | X | ||
| Secure Lookup | X | See Out Of The Box Algorithm Instances > Secure Lookup for all Secure Lookup algorithm instances | |
| Tokenization |
Configuring Your Own Algorithms¶
Algorithm Settings¶
The Algorithm tab displays algorithm Names along with Type and Description. This is where you add (create) new algorithms. The default algorithms and any algorithms you have defined appear on this tab.
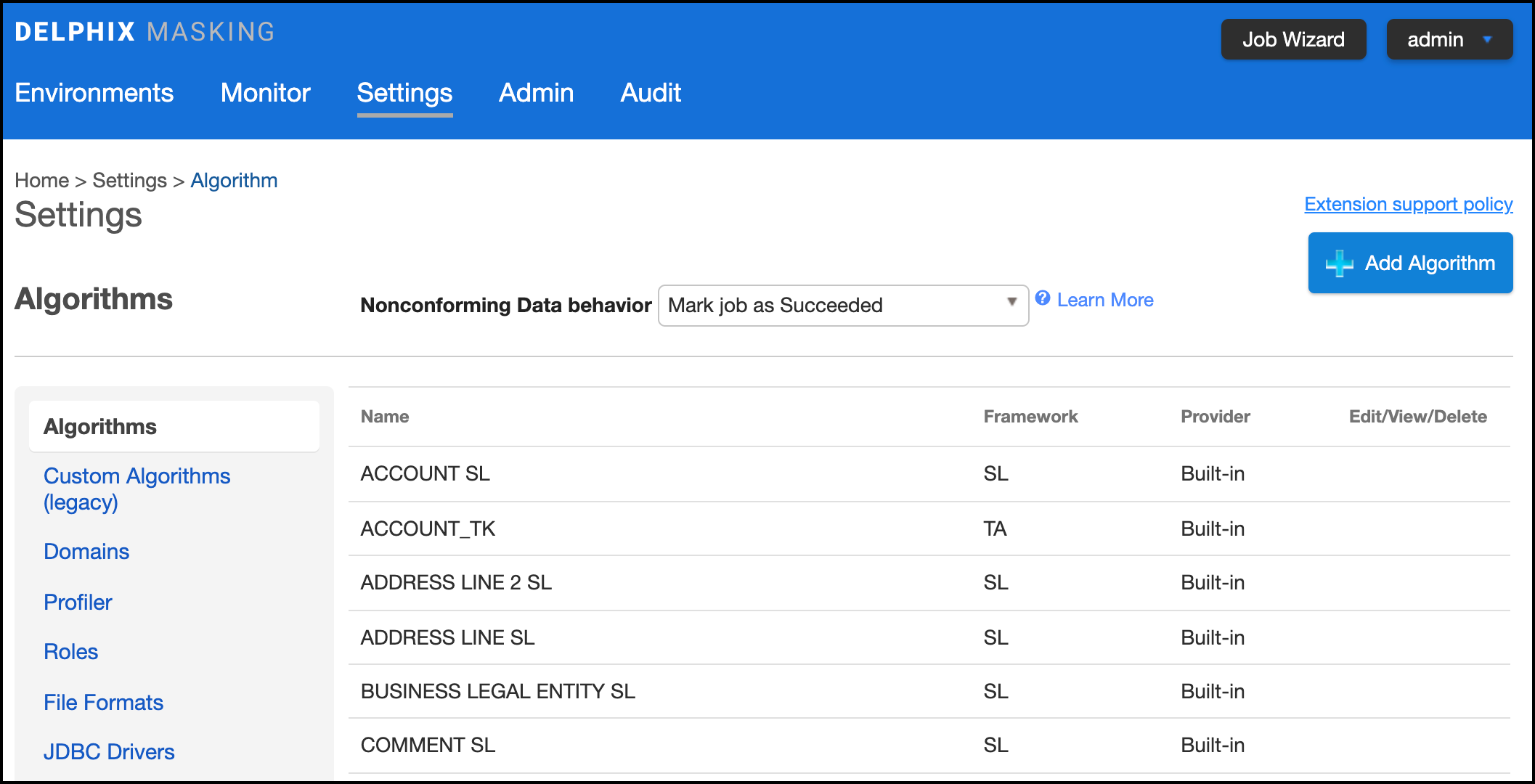
At the top of the page, Nonconforming Data behavior is displayed to specify how all algorithms should behave if they encounter data values in an unexpected format. Mark job as Failed instructs algorithms to throw an exception that will result in the job failing. Mark job as Succeeded instructs algorithms to ignore the non-conformant data and not throw an exception. Note that Mark job as Succeeded will result in the non-conformant data not being masked should the job succeed, but the Monitor page will display a warning that can be used to report the non-conformant data events.
Creating New Algorithms¶
If none of the default algorithms meet your needs, you might want to create a new algorithm. An algorithm that you create is called a "user-defined algorithm".
Algorithm Frameworks give you the ability to quickly and easily define the algorithms you want, directly on the Settings page. After you create an algorithm, your algorithm will be available to all users.
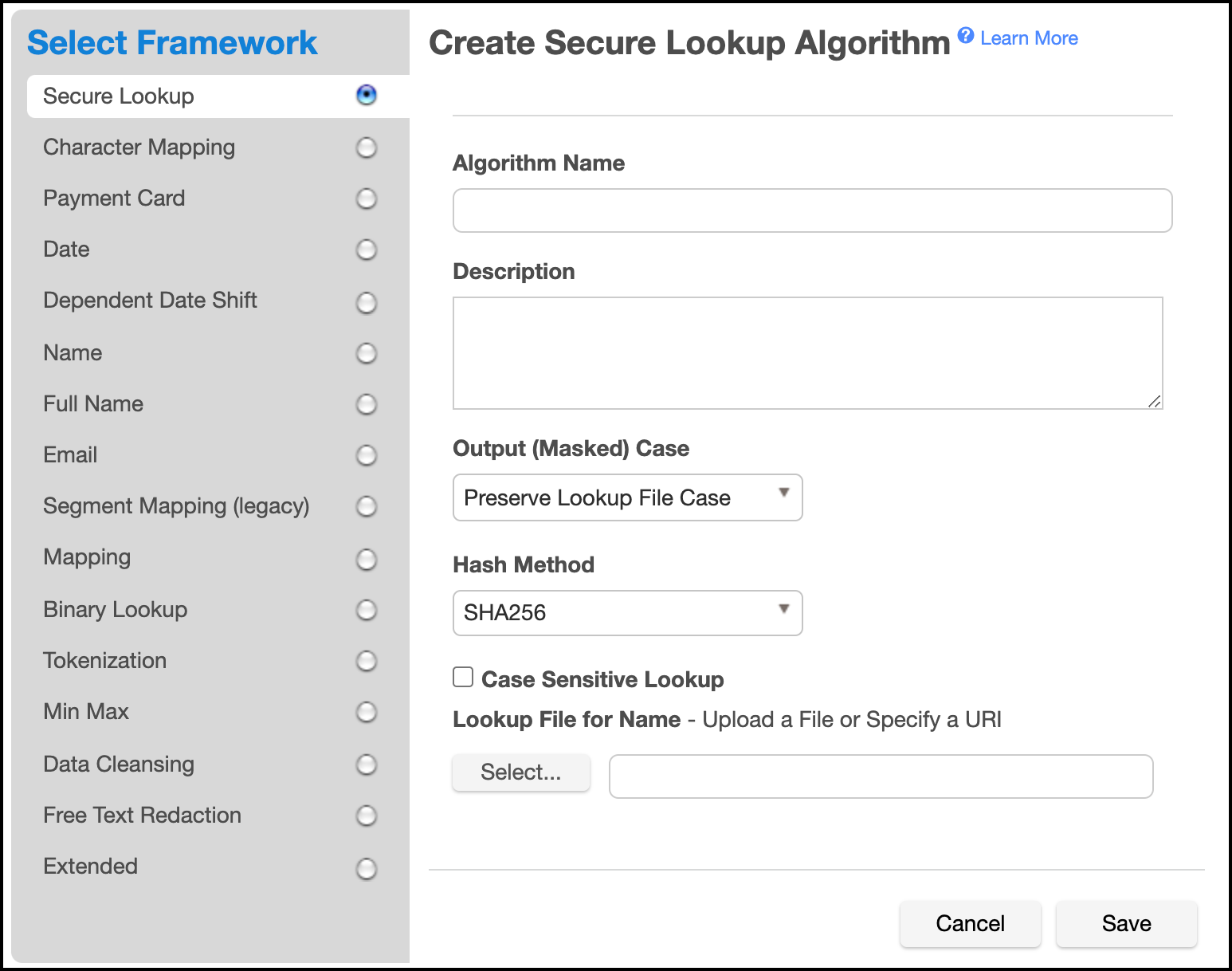
To add an algorithm:
-
In the upper right-hand corner of the Algorithm settings tab, click Add Algorithm.
-
Select an algorithm type.
-
Complete the form to the right to name and describe your new algorithm.
-
Click Save.
Editing Algorithms¶
Administrators can update system-defined algorithms. User-defined algorithms can be updated by the owner/user who created the algorithm.
Algorithm Frameworks Overview¶
Choosing an Algorithm Framework¶
See the Algorithm Frameworks section for a detailed description of each Algorithm Framework. The algorithm framework you choose will depend on the format of the data and your internal data security guidelines.
Choosing Between Character and Segment Mapping Frameworks¶
The Character Mapping algorithm is intended to replace Segment Mapping for many use cases. That said, it does not replicate every feature of that algorithm, so the specific masking application will determine which one is appropriate.
Reasons to choose Character Mapping over Segment Mapping:
- Character Mapping has no limit on the number of positions masked. Segment Mapping cannot handle inputs longer than 36 maskable characters.
- Character Mapping can mask all characters in the first Unicode plane. Segment Mapping can only mask "[a-zA-Z]" + "[0-9]"
- Character Mapping automatically preserves all non-masked characters. Segment Mapping requires configuration of all preserve characters, which can be impossible due to the limit on the number of preserve characters. Character Mapping is much easier to use when the data is potentially "dirty" or not consistently formatted.
- Character Mapping always changes the input (unless no maskable characters are present). With Segment Mapping, there is typically a small chance an input will mask to the same value.
- Character Mapping can process preserve ranges in reverse, allowing the last positions of an input to be preserved when inputs have different lengths. Segment Mapping preserve ranges are always processed from the beginning of input.
- Character Mapping uses a more complex masking computation, so that every maskable position influences every other position in the masked value. Segment Mapping pre-computes the permutations for each segment independently.
Reasons to choose Segment Mapping over Character Mapping:
- Segment mapping can mask different parts of the input, determined by position, differently. Character Mapping always masks the same groups of characters regardless of position.
- Segment mapping can map inputs to different outputs at a position, like { A, B, C, D } -> { W, X, Y, Z } by specifying different Real and Mask values. This is not possible with Character Mapping.
- Segment mapping supports numeric segments, with up to 4-digit segments masked to a specific range. Character Mapping doesn't allow this kind of range limiting.
- Segment Mapping can be used for tokenization. Character Mapping does not support tokenization at this time.